FOC: Current Control Design
1. Plant Model Equations
2. Control Structure
3. Control Parameters
a. Continuous Design
When it comes to the design of the field-oriented current control loop, the most common control structures make use of two simple PI-regulators. This is a good choice, because they are easy to implement and -correcty parameterized-, they fit our demands for the control system (see: Is PID control superior to PI-control?)
Many application notes and control unit manufacturers are recommending to parameterize the PI-controller gains by the use of the compensation control scheme, a special case of the optimum magnitude criteria. The calcultion is based on the fundamental electrical equations in the dq-reference frame:
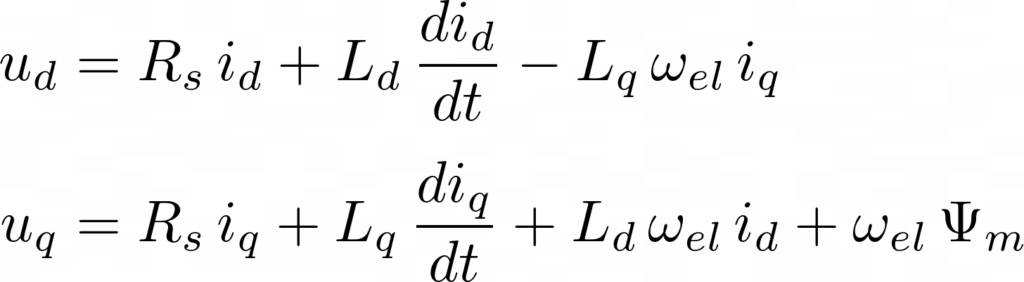
\[\begin{aligned}
u_d &= R_s \, i_d + L_d\,\frac{d i_d}{d t} – L_q\,\omega_{el}\,i_q
\\[3px]
u_q &= R_s \, i_q + L_q\,\frac{d i_q}{d t} + L_d\,\omega_{el}\,i_d + \omega_{el}\,\Psi_m
\end{aligned}\]
Now, let’s assume that we feedforward-compensated the coupling terms correctly and there are no distrubance terms (caused by harmonics, cross-couplings, interlocking-time…).
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.